 Open Source Software has risen to prominence lately. Briefly, Open Source Software (or OSS) are programs whose licenses permit users the freedom to run the program for any purpose, to modify the program, and to redistribute the original or modified program (without payment or restriction on who they can redistribute the program to). This article’s target is project managers who had heard about OSS but do not have an in depth idea about it. It will help them to decide whether or not OSS will prove useful in their upcoming project. This article begins by giving a brief introduction about Open Source Software, and some basic idea and concept about it. Then, it follows by an evaluation on a system based on OSS compare to proprietary software. Note that this article’s goal is not to show that all OSS is better than all proprietary software. Instead, it will simply compare commonly used OSS with commonly used proprietary software, to show that at least in certain situations and by certain measures, OSS is at least as good or better than its proprietary competition. At the end of this article, there will be a brief discussion and speculation on how Open Source Software and its development process may influence the architecture, management, processes, and atmosphere of the project.
Open Source Software has risen to prominence lately. Briefly, Open Source Software (or OSS) are programs whose licenses permit users the freedom to run the program for any purpose, to modify the program, and to redistribute the original or modified program (without payment or restriction on who they can redistribute the program to). This article’s target is project managers who had heard about OSS but do not have an in depth idea about it. It will help them to decide whether or not OSS will prove useful in their upcoming project. This article begins by giving a brief introduction about Open Source Software, and some basic idea and concept about it. Then, it follows by an evaluation on a system based on OSS compare to proprietary software. Note that this article’s goal is not to show that all OSS is better than all proprietary software. Instead, it will simply compare commonly used OSS with commonly used proprietary software, to show that at least in certain situations and by certain measures, OSS is at least as good or better than its proprietary competition. At the end of this article, there will be a brief discussion and speculation on how Open Source Software and its development process may influence the architecture, management, processes, and atmosphere of the project.
Introduction
Open Source is a term that refers to programming source code that is freely available to other developers, who can read, change, and redistribute the code throughout the development community. This can be in the form of fixing “bugs”, streamlining processes, or other modifications to improve the reliability and robustness of the code. The basic idea behind open source is very simple. According to the Open Source Initiative [8], “When programmers can read, redistribute, and modify the source code for a piece of software, the software evolves. People improve it, people adapt it, people fix bugs. And this can happen at a speed that, if one is used to the slow pace of conventional software development, seems astonishing.” The main features that characterize Open Source Software is the freedom that users have to:
- Use the software as they wish, for whatever they wish, on as many computers as they wish, in any technically appropriate situation.
- Have the software at their disposal to fit it to their needs. Of course, this includes improving it, fixing its bugs, augmenting its functionality, and studying its operation.
- Redistribute the software to other users, who could themselves use it according to their own needs. This redistribution can be done for free, or at a charge, not fixed beforehand.
It is important now to make clear that we are talking about freedom, and not obligation. That is, users of an open source program can modify it, if they feels it is appropriate. But in any case, they are not forced to do so. In the same way, they can redistribute it, but in general, they are not forced to do so. In order for the concepts of Open Source Software to work, any piece of these software must have access to its source code. The source code of a program, usually written in a high level programming language, is absolutely necessary to be able to understand its functionality, to modify it and to improve it. If programmers have access to the source code of a program, they can study it, get knowledge of all its details, and work with it as the original author would.
Advantages
Usually, the first perceived advantage of Open Source models is the fact that OSS is made available gratis or at a low cost. But this characteristic is not exclusive to Open Source Software, and several proprietary software products are made available in similar ways (a prominent case could be Microsoft’s Internet Explorer). What really distinguishes OSS from software available without fee is the combination of effects due to the characteristics discussed in previous section. All of them combined produce a synergistic impact, which is the cause of the real advantages of the open source model. Let us provide some more detail on how do these characteristics turn into advantages:
- The availability of the source code and the right to modify it is very important. It enables the unlimited tuning and improvement of a software product. It also makes it possible to port the code to new hardware, to adapt it to changing conditions, and to reach a detailed understanding of how the system works. This is why many experts are reaching the conclusion that to really extend the lifetime of an application, it must be available in source form. “No binary-only application more than 10 years old now survives in unmodified form, while several open source software systems from the 1980s are still in widespread use.” (Gonzalez- Barahona, Jesus, 2000).
- The right to redistribute modifications and improvements to the code, and to reuse other open source code, permits all the advantages due to the modifiability of the software to be shared by large communities. This is usually the point that differentiates open source software licenses from “nearly free” ones. In substance, the fact that redistribution rights cannot be revoked, and that they are universal, is what attracts a substantial crowd of developers to work around open source software projects.
- The right to use the software in any way. This, combined with redistribution rights, ensures (if the software is useful enough), a large population of users, which helps in turn to build up a market for support and customization of the software, which can only attract more and more developers to work in the project. This in turn helps to improve the quality of the product, and to improve its functionality. Which, once more, will cause more and more users to give the product a try, and probably to use it regularly.
As noted by Open Source Initiative [8], “Open source promotes software reliability and quality by supporting independent peer review and rapid evolution of source code.”
Disadvantages
The disadvantages of Open Source Software are few in number. What one person may see as a negative characteristic, another may see as positive. Some may think that the constant changes being made to the software are to their disadvantage, i.e. added functionality may not apply directly to their work. But on the other hand, if the changes are bug fixes or other improvements that can benefit everyone, then constant changes are a plus. So it generally depends on the software and the user’s individual needs.
Evaluation
As mentioned above, this article is not meant to prove that Open Source Software is better than proprietary software, but to provide all those statistics to compare various aspects between them. The main aim will be giving you a better idea whether or not OSS will serve you better in your upcoming project. In this section, I will be evaluating a typical information system that used for serving websites. Several benchmarking result and statistics done by several companies are presented so that you can make your own justification by the end of this article. We will be examining the most well known operating system and web server from both categories. We will be comparing Linux with Windows operating system, and Apache Web Server with Microsoft IIS (Internet Information Services). The comparison will be done on the following aspects.
Market Share
According to the survey conducted by Netcraft (www.netcraft.com), it have consistently shown Apache (an OSS web server) dominating the public Internet web server market ever since Apache became the number one web server in April 1996. For example, in November 2001, Netcraft polled all the web sites they could find (totaling 36,458,394 sites), and found that of all the sites they could find, Apache had 56.81% of the market, Microsoft had 29.74% of the market, iPlanet (aka. Netscape) had 3.59%, and Zeus had 2.20%.
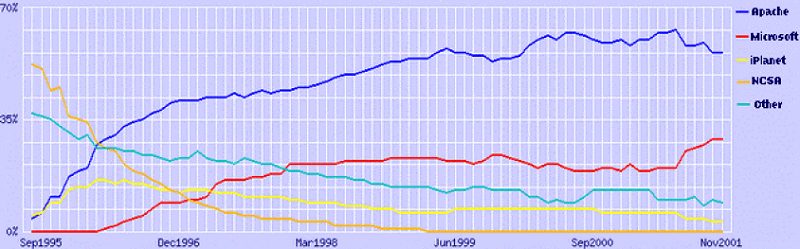
Market Share for Top Web Servers, Aug 1995 – Nov 2001 (Statistics Provided by Netcraft, www.netcraft.com)
More recently, Netcraft has been trying to discount “inactive” sites, since recently many sites have been deployed that are simply “placeholder” sites not being actively used. When counting only active sites, Apache does even better; by November 2001, Apache had 61.88% of the web server market, Microsoft had 26.40%, iPlanet 1.48%, and Zeus 0.04%.
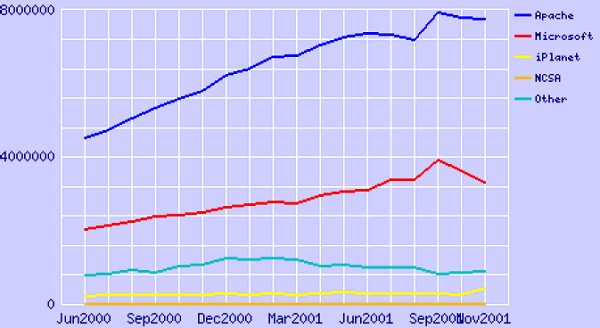
Market Share for Active Web Servers, Jun 2000 – Nov 2001 (Statistics Provided by Netcraft, www.netcraft.com)
A lot of people thought that most computer in the world running on Microsoft Windows. This is true for home computing, but not in the arena of Internet servers. A recent survey done by Zoebelein [1] in April 1999 found that, of the total number of servers deployed on the Internet in 1999 (running at least ftp, news, or http) in a database of names they used, the number one operating system was Linux (at 28.5%), with others trailing. Here’s how the various operating system fared in the study.
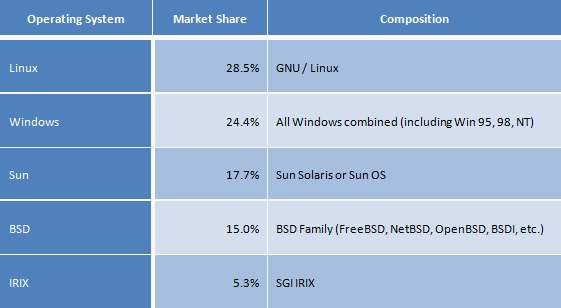
Market Share for Major Operating System used as Internet Servers (Statistics Provided by Zoebelein, www.leb.net/hzo/ioscount)
A portion of the BSD family is also OSS, so the OSS operating system total is even higher; if over 2/3 of the BSDs are OSS, then the total share of OSS would be about 40%.
Reliability
ZDnet had run a 10-month reliability test to compare the reliability of different operating systems. The operating system that they had chosen was Caldera Systems OpenLinux, Red Hat Linux, and Microsoft’s Windows NT Server 4.0 with Service Pack 3. All three used identical (single-CPU) hardware, and network requests were sent to each server in parallel for standard Internet, file, and print services. The result: NT crashed an average of once every six weeks, each taking about 30 minutes to fix; that’s not bad, but neither GNU/Linux server ever went down. This ZDnet article also does a good job of identifying GNU/Linux weaknesses (e.g., desktop applications and massive SMP).
Another test was carried out by Syscontrol to measure the reliability of Microsoft IIS web server, compare to Apache web server. They measured over 100 popular Swiss web sites over a three-month period, checking from 4 different locations every 5 minutes. The results are:
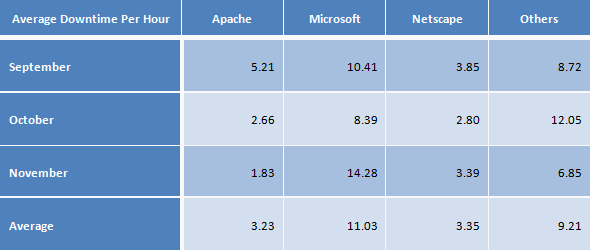
Syscontrol AG’s Analysis of Website Uptime (www.syscontrol.ch, February 7, 2000)
Performance
In the recent performance test on file servers done by PC Magazine in November 2001 [2], they found that Linux with Samba significantly outperformed Windows 2000 Server when used as a file server for Microsoft’s own network file protocols. This was true regardless of the number of simultaneous clients (they tested a range up to 30 clients), and it was true on the entire range on computers they used (Pentium II/233MHz with 128MiB RAM, Pentium III/550MHz with 256MB RAM, and Pentium III/1GHz with 512MB RAM).
Besides this, the following are several claims result of some experiment and test done by several companies:
- Ziff-Davis found that GNU/Linux with Apache beat Windows NT 4.0 with IIS by 16%-50% depending on the GNU/Linux distribution.
- Mindcraft released a report in April 1999 that claimed that Microsoft Windows NT Server 4.0 is 2.5 times faster than Linux (kernel 2.2) as a File Server and 3.7 times faster as a Web Server when running on a 4-CPU SMP system. [5]
- Network Computing found that GNU/Linux with Samba ran at essentially the same speed as Windows for file serving. [3]
- The German magazine found that web sites with NT was better at static content and dual network connections, but GNU/Linux was better for sites with dynamic content and single connections. [4]
Despite there were a lot of test result and claims available on the web, I had discarded a few of them as the test wasn’t carried out in a fair manner. For example, a more recent set of articles from eWeek on June 2001, shows some eye-popping performance numbers for GNU/Linux with TUX. However, although they compare it to Microsoft IIS, they don’t include Microsoft’s SWC (Scaleable Web Cache), Microsoft’s response to TUX – and omitting it makes this comparison unfair in my opinion.
Security
Security is one of the major concerns to most IT administrator. Bugtrag had been keeping a vulnerability database to keep track of the security issues of various operating systems. The Bugtraq vulnerability database suggests that the least vulnerable operating system is Open Source, and that all the OSS operating systems in its study were less vulnerable than Windows in 1999-2000. An analysis of one database is the Bugtraq Vulnerability Database Statistics page [7], As of September 17, 2000, here are the total number of vulnerabilities for some leading operating systems:
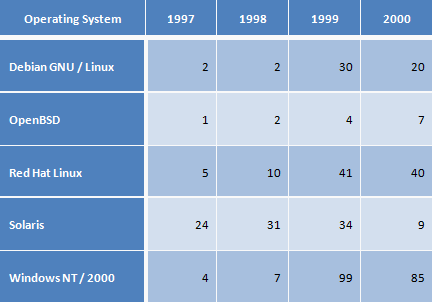
Vulnerability Database Statistics (www.securityfocus.com, September 17, 2000)
Although you might argue that those OS with small market shares are likely to have less analysis, thus produce a lower result in the statistics. But we have seen from the previous section, that GNU/Linux is the number one or two server OS. Still, this clearly shows that the three Open Source OSs listed (Debian GNU/Linux, OpenBSD, and Red Hat Linux) did much better by this measure than Windows in 1999 and (so far) in 2000. Even if a bizarre GNU/Linux distribution was created explicitly to duplicate all vulnerabilities present in any major GNU/Linux distribution, this intentionally bad GNU/Linux distribution would still do better than Windows (it would have 88 vulnerabilities in 1999, vs. 99 in Windows). The best results were for OpenBSD, an Open Source operating system that for years has been specifically focused on security. It could be argued that its smaller number of vulnerabilities is because of its rarer deployment, but the simplest explanation is that OpenBSD has focused strongly on security – and achieved it better than the rest.
The development process of OSS
When people approach the Open Source movement, one of the first questions is something like “why did all those people make such a good software without a clear reward in terms of money?”’ The answer is difficult to explain only in terms of money and personal expectations. In several cases, there is a clear expectancy of economic reward (this is in fact usually the case when it is a company who leads an Open Source project). But in many other cases, the reason that impels programmers to start, contribute and maintain open source projects is not directly related to economic rewards. For many people, programming is considered as a highly rewarding activity in itself. As such, contribution to open source projects can even start as a hobby, or as a side effect of some University or School assignment. The reward of coding is also greatly amplified by the fact that the code is in use by people, and that a community starts to gather around and discuss specific functionality, design, and coding issues.
The Cathedral and the Bazaar
The two words, “cathedral” and “bazaar” were used by Eric Raymond in his book “The cathedral and bazaar” published in 1998 [6]. In it, the author sheds some light on the problem of how successful open software projects are managed. One of them, which he calls “cathedral-like development” (as an analogy with how Middle Age cathedrals were built), is characterized by a relatively strong control on design and implementation. The other one, which he calls “bazaar-like development”, is based on informal communication between the coders, and several small and medium coding efforts that can be chosen at will by the volunteers (as in a bazaar, where everyone can choose what he wants).
The cathedral-like is the traditional style of software management, although it is also used by some open source projects. In this model, there is a strong control on who can submit patches to the code, and how they are integrated, a clearly defined management structure, and a rigorous plan for code releases. On the other hand, the bazaar-like style uses a loose policy on code releases, and relatively informal control over who can provide patches for bugs or new functionality. The model can be characterized with a sentence: “code often, release often”. This usually translates to a situation where long-standing stable versions are available for general use, while the project follows on adding new features and fixing bugs in rapidly evolving development versions. While the former are released only from time to time, using higher quality assurance procedures, the latter are released with high frequency, so that programmers and users willing to test and improve those development versions can do it. Every time a new function is added, the code is released as a widely distributed development version. Sometimes this process is even extended to the code management system, so that anyone can get a current “snapshot” of what the programmers are working on at any given time.
Economics of Open Source Software
The economic impact of Open Source models is going to be very high, not only in the software industry, but in society in general. There are several new economic models for Open Source projects will be presented (externally funded, internally funded, unfunded, and internally used). These new economic models are important because many traditional models of the software industry are heavily based on proprietary software where the income is directly related to per-copy price (particularly in the case of shrinkwrapped software). With some exceptions, these traditional models are not viable with Open Source software, since income cannot come from selling copies of the software (freedom of redistribution tends to set the price at the point where marginal cost of reproduction is near zero). Therefore, Open Source business must look for other sources of income.
For an Open Source projects that is externally funded, the organization or company that develop Open Source Software through the initiative (at least in the financial sense) of some external organization. Usually those external entities determine how the funds are to be spent, and where the development efforts are headed. The developer entity just follows those more or less strict guidelines. In some sense, it could be said that the external entity ‘sponsors’ the development of some given open source software.
Some projects can get started as a lower-cost alternative to proprietary systems. In this case, the developer company does not have (at least in the beginning) any plan to get external income related to the sale of the software or services related to it. The company develops some system because it is useful for them, and later decides to make it Open Source, and distribute it widely, just to benefit from the Open Source development source. Probably they will get some contributions, improvements and bug fixes from external developers interested in the software, and some bug reports. Later on, the product may even reach some market acceptance, and the developer company could even get some economic benefits from it.
If there is enough ‘network effect’, there may be no need for funding, just a minimal effort for the organization of releases and patches. Examples of these kinds of open source projects are the Linux kernel, GNU/Linux distributions like Debian, BSDbased operating systems such as FreeBSD, NetBSD, or OpenBSD, and the Mesa OpenGL-like library. These efforts started in many cases as the effort of a single man, or of a small group, and through good organization and volunteer work they created an extended networked structure that maintains the code. Even with some (limited) funding for some projects, all of these efforts become successful without an external grant or without explicit money offerings. In fact, this is the case for hundreds of small open source projects.
Conclusion
I had discussed Open Source Software from various point of view. I tried to provide to the reader a relatively detailed and as complete as possible introduction to the Open Source Software landscape. I had even provide some test experiment done by several companies to show how Open Source Software performs in the industry. I hoped to have shown the main characteristics of this technology, which, although has already a long history, is still unknown to many people. I had also tried to expose the main features of Open Source Software, and the mechanisms which drive the working of Open Source projects which enable these features. In my opinion, Open Source Software has already started to modify the rules in the information technology industry, which will produce enormous changes in the years to come. Given these facts, it is clear that those countries and companies which adopt Open Source technologies in the short term will have a huge competitive advantage, and that society in general can benefit a lot from this early adoption.
References
- “The Internet Operating System Counter”, http://www.leb.net/hzo/ioscount
- O. Kaven, “Performance Tests: File Server Throughput and Response Times”, 2001. http://www.pcmag.com/article2/0,2817,16227,00.asp
- G. Shipley, “Is It Time for Linux”, May 31, 1999. http://www.networkcomputing.com/1011/1011f1.html
- J. Schmidt, “Linux and NT as Web Server on the Test Bed”, 1999. http://www.heise.de/ct/english/99/13/186-1/
- “Web and File Server Comparison”, April 13, 1999. http://www.mindcraft.com/whitepapers/nts4rhlinux.html
- E. Raymond, “The Cathedral and the Bazaar”, 2000. http://www.catb.org/~esr/writings/cathedral-bazaar/cathedral-bazaar/
- “Bugtraq Vulnerability Database Statistics”, 2000. http://www.securityfocus.com/frames/?content=/vdb/stats.html
- The Open Source Initiative, 2001. http://www.opensource.org/
- J. Kirch, Microsoft Windows NT Server 4.0 versus UNIX, 1999. http://web.archive.org/web/20010801155417/www.unix-vs-nt.org/kirch/
- E. Raymond, “Goodbye, ‘free software’; hello, ‘open source’”, 1998. http://www.tuxedo.org/~esr/open-source.html
- D. Cubranic, “Open Source Software Development”. http://sern.ucalgary.ca/~maurer/ICSE99WS/Submissions/Cubranic/Cubranic.html


